We’re announcing Kanon Answer Extractor and Kanon Answer Extractor Mini, the world’s best legal extractive question answering models, which outperform OpenAI’s GPT-4.1 by over 90%.
You can get started building your own legal AI solutions atop our answer extractors using our newly released extractive question answering API.
As extractive question answering models, Kanon Answer Extractor and Kanon Answer Extractor Mini excel at pulling out answers to questions from legal documents, whether it’s as simple as “what is the governing law of this contract?” or as complex as “what doctrine did the judge rely on in making her decision?”.
Because answers are taken directly and exclusively from users’ inputs, our answer extractors are immune from the sort of hallucinations that typically plague generative models. They are also significantly faster, more precise, and otherwise cost-effective than generative models by virtue of being specialized for a single, domain-specific task.
Indeed, we pitted our answer extractors against some of the best generative models as well as the top general-purpose extractive question answering models and found our models to significantly outperform them when evaluated on LegalQAEval, the only extractive question answering benchmark set for the legal domain.
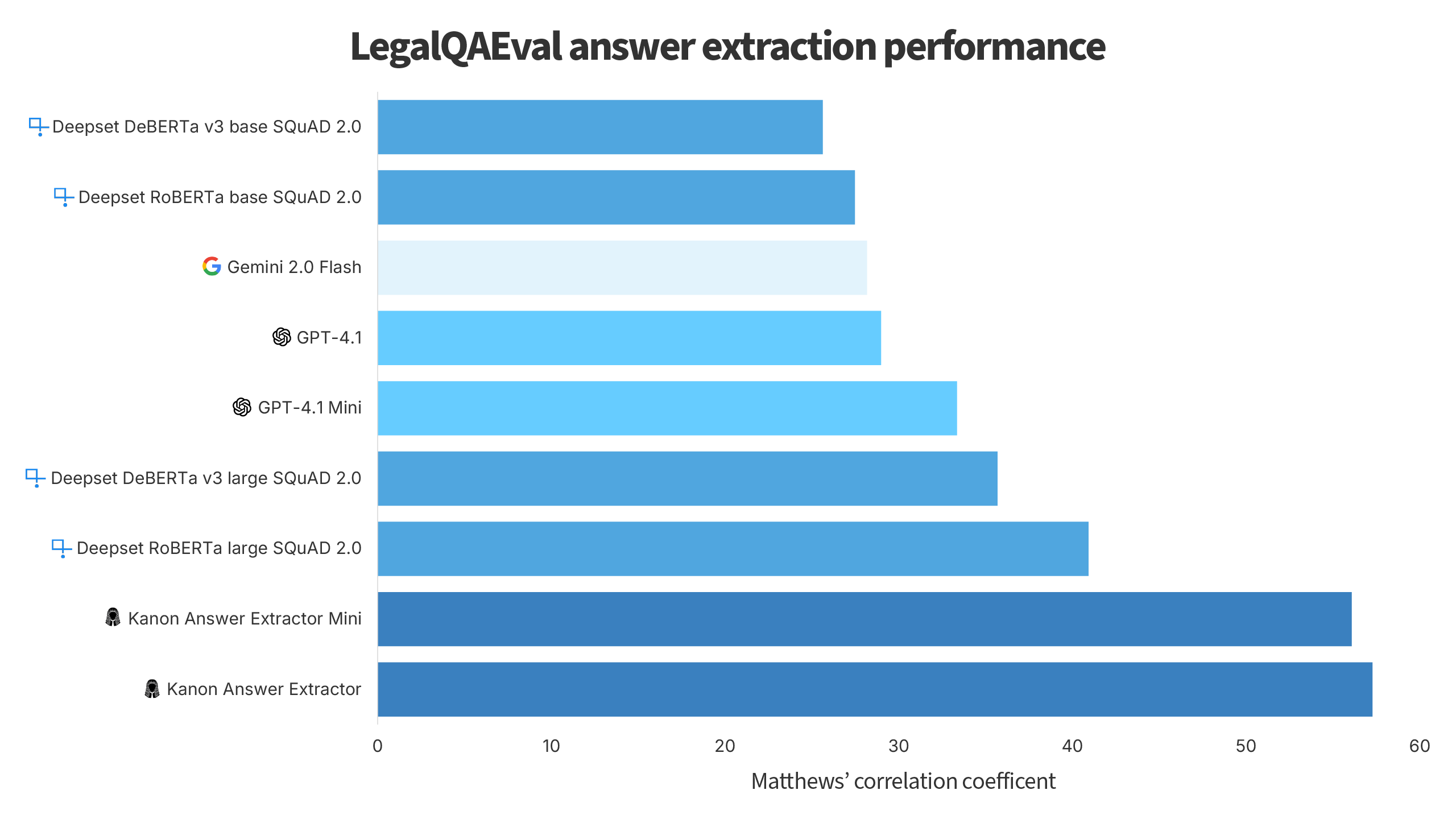
To take into account both the ability of models to determine when a question has an answer that is extractable from a particular text as well as their ability to extract the correct answers from texts, we evaluated the models as if they were classification models, where a ground label would only be positive if an example had an answer and the prediction would only be positive if the answer was correctly extracted by a model (correct in this context meaning that the answer had a Levenshtein similarity to any of the ground truth answers that was greater than 0.4). We then used Matthews’ correlation coefficient, widely regarded as the gold standard for evaluating the balanced predictive power of classifiers, to determine the overall performance of the models.
To ensure the reproducibility of our benchmarks, we’ve publicly released our benchmarking code on GitHub under an open-source license and are sharing accuracy scores and other metrics collected in our evaluation here.
We’ve also added a short guide on how you can use our answer extractors to our documentation available here. We will soon start supplementing our user guides with more practical tutorials and how-tos that have been applied to our most common use cases.
With our answer extractors completed, next on our roadmap is our crown jewel for 2025: high performance, high accuracy, industry-grade legal embedding models embodying all the learnings we’ve made over the past year. You can get notified when that drops by following us on LinkedIn, Twitter or Reddit.