tl;dr
We’re announcing the release of Kanon 2 Embedder, the world’s best legal embedding model, ranking first on the Massive Legal Embedding Benchmark (MLEB) as of 16 October 2025.
Kanon 2 Embedder is available for use today on the Isaacus API. Importantly, unlike other high scoring models on MLEB, Kanon 2 Embedder is also privacy and security friendly — none of your data is used to train our models by default (compare, for example, Voyage AI, Cohere, and Jina) — and can be self-hosted for enterprises with heightened security or reliability requirements.
29 October 2025: Kanon 2 Embedder is now available for self-hosting via private, air-gapped containers on the AWS Marketplace.
The top 4 models on MLEB by NDCG@10 score
Kanon 2 Embedder is the world’s best legal embedding model
Despite being many times smaller, Kanon 2 Embedder beats the performance of OpenAI’s best embedding model, Text Embedding 3 Large, by 9% on MLEB, while simultaneously being 30% quicker than their fastest current generation embedder, Text Embedding 3 Small.
Thanks to its extreme parameter efficiency, Kanon 2 Embedder further sets the new Pareto frontier in balancing inference time with legal information retrieval performance. In fact, it is the fastest of all commercial models currently on MLEB.
NDCG@10 score vs inference time on MLEB
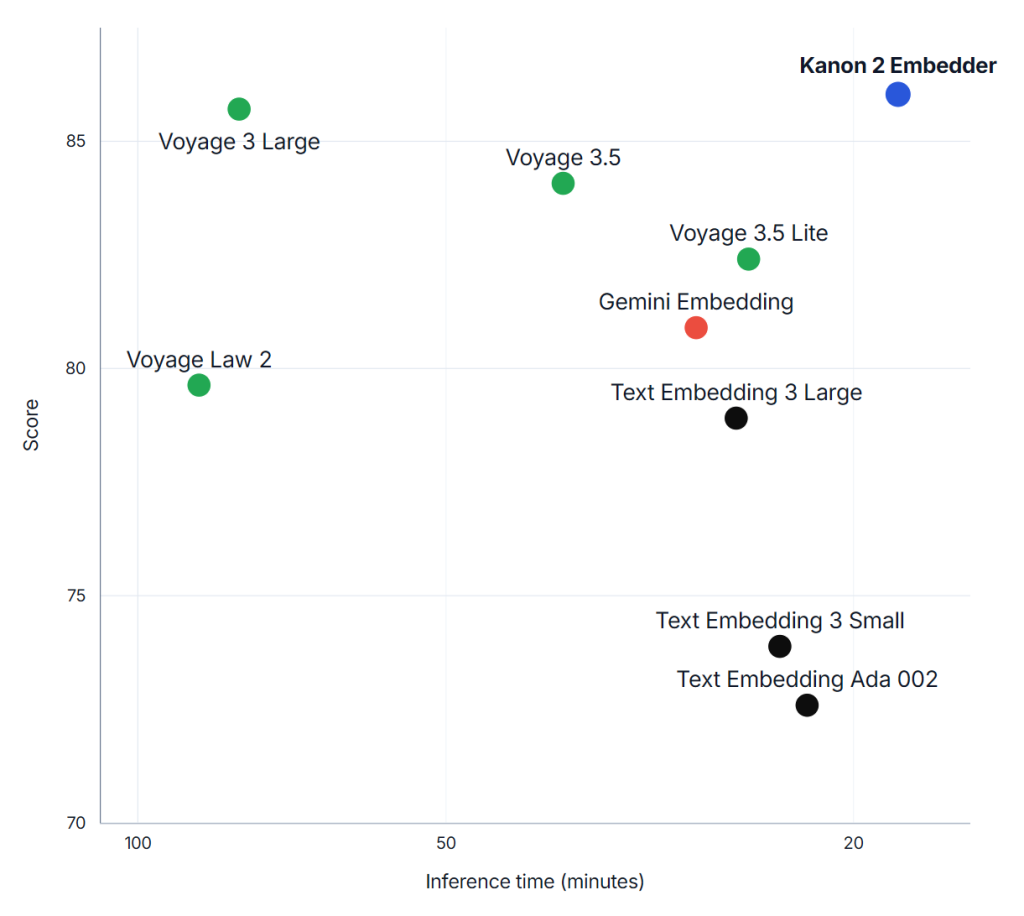
Compared to Voyage 3 Large, another much larger LLM, which ranks second on MLEB, Kanon 2 Embedder is more accurate, 340% faster, and, importantly, is privacy friendly, with no user data being used to train Isaacus models or improve Isaacus services by default (see, by contrast, Voyage AI’s terms of service).
Kanon 2 Embedder also ranks first on judicial and regulatory tasks, while ranking third on contractual tasks, slightly under Voyage 3.5 and Voyage 3 Large.
Out of the 10 tasks that make up MLEB, Kanon 2 Embedder comes first on 5. Apart from Voyage 3 Large, which ranks first on two datasets, no other models rank first more than once.
|
Rank
|
Model
|
Score
|
Caselaw
|
Contracts
|
Regulation
|
|---|
Improving on the original Kanon model, which had a context window of 512 tokens, the Kanon 2 foundation model (on which Kanon 2 Embedder is based) has a significantly expanded context window of 16,384 tokens.
Additionally, like other modern text embedding models, Kanon 2 Embedder is Matryoshka-aware, supporting truncation 1,024, 768, 512, and 256 dimensions, with its default and maximum dimensionality being 1,792.
At 768 dimensions, Kanon 2 Embedder continues to rank first on MLEB. At 512 and 256 dimensions, it drops to second place, only slightly under Voyage 3 Large.
Kanon 2 Embedder remains number one on MLEB at 768 dimensions
How we did it
We attribute Kanon 2 Embedder’s outstanding performance to, primarily:
- Enormous amounts of high-quality legal training data — Kanon 2 Embedder was pretrained on billions of legal tokens and trillions of non-legal tokens, after which it was finetuned on millions of legal query-document pairs, all of which were curated and reviewed by experts.
- Improved training recipe — our team developed never-before-publicized improvements to the standard training recipe for text embedding models, including novel methods for pooling, temperature scaling, Matryoshka reinforcement learning, and weakly supervised pretraining, that allowed it to punch well above its weight.
- Improved architecture — Kanon 2 Embedder leverages the latest improvements to the original Transformer architecture, such as dynamic context window scaling, kernel fusion, and quantization, to significantly speed up both training and inference time.
By stacking these innovations on top of each other, we managed to produce a legal embedding model that is not only more accurate than much larger state-of-the-art models, but also considerably more efficient.
What’s next for Isaacus
Kanon 2 Embedder marks the beginning of a new era for Isaacus. Our vision is to solve every common AI- and data-related pain point of the legal tech industry, from building reliable and robust domain benchmarks to training state-of-the-art legal AI models that redefine what’s possible.
Over the coming months, we aim to release the world’s first legal grounding API, allowing legal tech professionals to plug their models into the Blackstone Corpus, our private, living repository of high-quality legal data, to build their own legal AI applications, from search engines to chatbots.
We will be baking Kanon 2 Embedder directly into our grounding API to ensure our customers always get what they’re looking for.
If you’d like to be part of our journey to push the boundaries in legal AI, we encourage you to join our platform, explore our docs, and reach out.
Additionally, you can stay up to date on our progress by following us on LinkedIn and Reddit.
25 October 2025: since posting this, Jina AI has clarified to Isaacus that they are not training and have not trained on user data.