tl;dr
We’re announcing the release of the Massive Legal Embedding Benchmark (MLEB), the largest, most diverse, and most comprehensive benchmark for legal text embedding models.
MLEB contains 10 datasets spanning multiple document types, jurisdictions, areas of law, and tasks.
To do well on MLEB, embedding models must demonstrate both extensive legal domain knowledge and strong legal reasoning skills.
On MLEB, our newly released Kanon 2 Embedder legal embedding model scores highest while simultaneously maintaining the lowest inference time of all commercial competitors, highlighting the extreme accuracy and efficiency gains to be had from domain adaptation.
23 October 2025: MLEB has since been published as a paper, available now on Arxiv.
The top 4 models on MLEB by NDCG@10 score
The need for an industry-standard legal embedding benchmark
In the process of training Kanon 2 Embedder, we found that the only two existing benchmarks for legal embeddings, LegalBench-RAG and the legal split of the Massive Text Embedding Benchmark (MTEB), were either of low quality or low diversity.
With regard to LegalBench-RAG, we found that it included only 4 evaluation datasets, and all datasets consisted entirely of contracts. In practice, legal professionals and users seeking legal advice or knowledge tend to search for and be interested in a much broader range of document types, including legislation, regulations, cases, and general legal literature. Additionally, the datasets were largely dominated by US contracts, reflecting the broader overrepresentation of American law in legal benchmarks and public legal datasets.
In respect of the legal split of MTEB, we observed two key issues.
First, we found a significant amount of mislabeling.
AILA Casedocs and AILA Statutes, in particular, comprising 25% of the legal split and 40% of English data in the split, contain many query-passage pairs that are totally irrelevant to each other. Upon review of the authors’ paper, we discovered the cause to be that the datasets had been created using an ‘automated methodology’ that paired ‘facts stated in certain [Indian] Supreme Court cases’ with cases and statutes that had been ‘cited by the lawyers arguing those cases’. According to the authors, ‘actually involving legal experts (e.g., to find relevant prior cases / statutes) would have required a significant amount of financial resources and time’.
The second issue we found with the legal split of MTEB was that it lacked diversity in the areas that matter most to legal practitioners and seekers of legal knowledge.
Of the remaining English-language datasets after exclusion of AILA Casedocs and AILA Statutes, two deal with consumer terms of service (Consumer Contracts QA and Legal Summarization), leaving only one (Corporate Lobbying) that deals with legislation, and none dealing with case law. All such datasets are again largely representative of American law.
Regarding the non-English-language datasets in the legal split of MTEB, we argue that, in many cases, the legal systems of different cultures may fundamentally differ in ways that make cross-jurisdictional comparisons (e.g., between the common law system used by Anglosphere countries and Sharia law) of the effectiveness of legal embeddings inappropriate.
Furthermore, given that the legal split contains two German datasets, one Chinese dataset, and no other non-English datasets, and that those datasets are concentrated on three select legal tasks, we argue that the inclusion of non-English datasets largely introduces bias and noise in ways that are unlikely to be conducive to real-world performance on most English-language legal information retrieval tasks.
What makes MLEB an industry-standard benchmark
Learning from the limitations of existing legal embedding benchmarks, we designed MLEB with four key objectives in mind, namely to:
- be of high quality, both in terms of provenance and labeling;
- consist of text processing tasks that have genuine real-world utility to legal tech professionals;
- be meaningfully challenging in ways likely to require significant legal knowledge and strong legal reasoning skills; and
- represent a broad variety of jurisdictions, legal areas, and types of legal texts.
To that end, MLEB contains 10 different evaluation sets spanning a range of difficulties (including tasks requiring legal reasoning as well as tasks requiring lexical analysis), problem types (specifically, retrieval, zero-shot classification, and question answering), jurisdictions (the US, UK, Australia, Ireland, Singapore, and the EU) and document types (decisions, legislation, regulations, contracts, and literature).
Of the 10 datasets in MLEB, 7 are entirely new, constructed either by having subject matter experts hand-label data or by adapting existing expert-labeled data.
One of the most valuable constituents of MLEB is the Australian Tax Guidance Retrieval dataset. This dataset pairs 112 real-life tax questions posed by Australian taxpayers with 105 relevant Australian Government guidance and policy documents.
We constructed this dataset by sourcing questions from the Australian Taxation Office’s community forum, where Australian taxpayers ask accountants and ATO officials their tax questions. We found that, in most cases, such questions can be answered by Australian Government guidance materials that, for whatever reason, taxpayers were unable to locate themselves. Accordingly, we manually went through a stratified sample of challenging forum questions and extracted guidance materials linked to by tax experts that we confirmed to answer such questions.
What makes this dataset so valuable is that, unlike the vast majority of legal information retrieval evaluation sets currently available, this dataset consists of genuine, challenging real-world user-created queries, rather than artificially constructed queries that, at times, diverge considerably from the types of tasks embedding models are actually used for.
The queries are valuable and challenging precisely because users have gone to the effort of asking them on a forum, indicating that traditional search engines failed to surface the answers they were looking for. The relevant materials are, in turn, also valuable because accountants and ATO officials have confirmed them to be relevant, and we have independently affirmed their relevance.
This dataset is just one of several others that we invested considerable, painstaking effort into ensuring the usefulness and quality of.
Below, we present an overview of all the datasets included in MLEB alongside all the various features that make them unique.
|
Name
|
Document type
|
Jurisdiction
|
Creators
|
Description |
|---|---|---|---|---|
| Bar Exam QA | Judicial | US | Stanford RegLab (Zheng et al) | US bar exam questions paired with relevant caselaw. |
| SCALR | Judicial | US | Faiz Surani and Varun Iyer | Questions presented to the US Supreme Court paired with descriptions of the Court's final holdings. |
| Singaporean Judicial Keywords | Judicial | Singapore | Isaacus (Umar Butler) | Judicial catchwords paired with Singaporean court judgments. |
| GDPR Holdings Retrieval | Judicial | EU | Isaacus (Umar Butler and Abdur-Rahman Butler) | GDPR case fact patterns paired with descriptions of court holdings. |
| Australian Tax Guidance Retrieval | Regulatory | Australia | Isaacus (Abdur-Rahman Butler and Umar Butler) | Australian tax law questions paired with relevant Australian Government tax guidance and policies. |
| Irish Legislative Summaries | Regulatory | Ireland | Isaacus (Umar Butler) | Long titles paired with Irish acts. |
| UK Legislative Long Titles | Regulatory | UK | Isaacus (Umar Butler) | Long titles paired with UK acts. |
| Contractual Clause Retrieval | Contractual | Multinational | Isaacus (Umar Butler) | NLI-style descriptions of types of contractual clauses paired with examples of those clauses. |
| License TL;DR Retrieval | Contractual | Multinational | Isaacus (Abdur-Rahman Butler) | Summaries of software licenses paired with their full texts. |
| Consumer Contracts QA | Contractual | Multinational | Noam Kolt | Questions about online terms of service paired with relevant clauses. |
As part of our long-standing commitment to open and accessible legal data, AI, and tech, we’ve ensured that MLEB and all its constituent datasets are licensed as permissively as possible. We’ve also publicly released our evaluation code and raw results on GitHub to assist with the consistent and reproducible evaluation of models on MLEB.
How models fare on MLEB
As of 16 October 2025, Kanon 2 Embedder, our newly released legal embedding model, ranks first on MLEB with an NDCG@10 score of 86%, followed by Voyage 3 Large at 85.7%.
|
Rank
|
Model
|
Score
|
Caselaw
|
Contracts
|
Regulation
|
|---|
Interestingly, we find that the qualities that make an embedding model good at general multilingual information retrieval tasks are not necessarily the same as those that make a model good at legal information retrieval.
Gemini Embedding ranks 1st on MTEB and Voyage 3.5 ranks 23rd, whereas on MLEB, Gemini is only 7th and Voyage 3.5 is 3rd.
We observe that strong performance on MLEB seems to correlate with legal domain adaptation.
Last year, Harvey announced they had partnered with Voyage to train a custom embedding model on private legal data, which may explain, in some part, why they outperform Qwen, Gemini, OpenAI, and Jina models.
We note, however, that there is, unfortunately, a serious risk that Voyage’s models were trained on some of the evaluation sets in MLEB due to the fact that Voyage trains on their customers’ private data by default (which would invariably include benchmarks). This is also a risk for Cohere and Jina models.
Nevertheless, despite also being much smaller in size than Voyage 3 Large, Kanon 2 Embedder manages to punch far above its weight thanks to the enormous amounts of high-quality, licensed legal data it was trained on alongside several design improvements our team made to the standard recipe for building an embedding model.
Kanon 2 Embedder takes the number one spot in overall performance as well as in the domains of caselaw and regulation. It is also third best at tasks involving contracts, coming slightly under Voyage 3.5 and Voyage 3 Large.
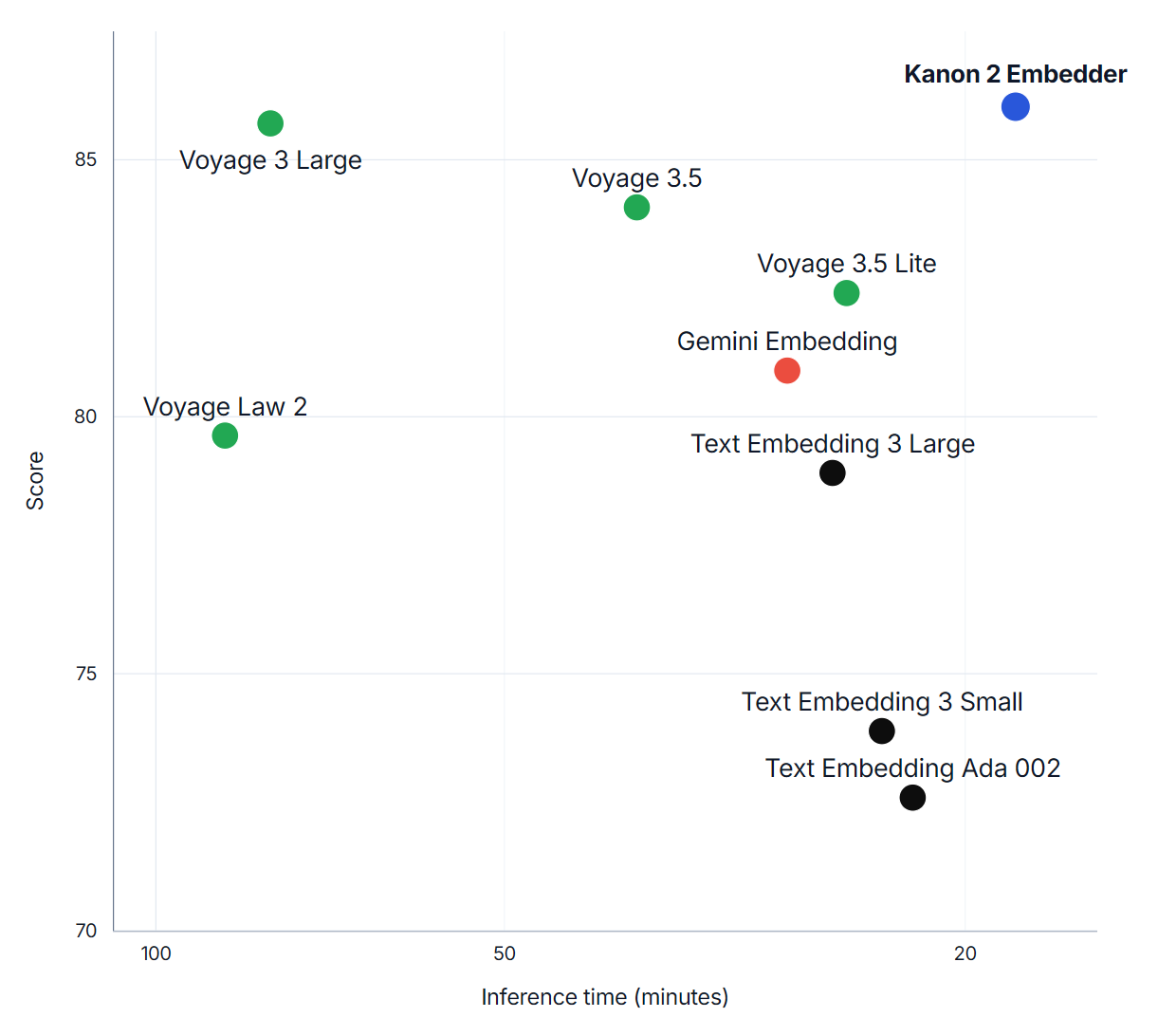
Additionally, due to its extreme parameter efficiency, Kanon 2 Embedder manages to set the new Pareto frontier in balancing inference time with accuracy. Indeed, of all the commercial models we tested, Kanon 2 Embedder was the fastest. Compared to Voyage 3 Large, in particular, our model was four times faster.
NDCG@10 score vs inference time on MLEB
Where to next for Isaacus
This is only the beginning for us. Our vision is to solve every common AI- and data-related pain point of the legal tech industry, from building reliable and robust domain benchmarks to training state-of-the-art legal AI models that redefine what’s possible.
Over the coming months, we aim to release the world’s first legal grounding API, allowing legal tech professionals to plug their models into the Blackstone Corpus, our private, living repository of high-quality legal data, to build their own legal AI applications, from search engines to chatbots.
We will be baking Kanon 2 Embedder directly into our grounding API to ensure our customers always get what they’re looking for. We also plan on contributing portions of the Blackstone Corpus, as we have already done, back into the open-source community, including into MLEB.
If you’d like to be part of our journey to push the boundaries in legal AI, we encourage you to join our platform, explore our docs, and reach out.
You can also stay up to date on our progress by following us on LinkedIn and Reddit.
Notes:
- Unfortunately, because Cohere’s terms of service entirely forbid benchmarking as well as forbidding competitors from joining their platform, none of their models could be included in MLEB. We note that Cohere was the only commercial provider we encountered with such terms.
- 25 October 2025: Since posting this, Jina AI has clarified to Isaacus that they are not training and have not trained on user data.