tl;dr
We’re publicly releasing Kanon 2 Enricher, the world’s first hierarchical graphitization model, capable of transforming unstructured documents of any length into rich, highly structured knowledge graphs with sub-second latency.
We’re also releasing the Isaacus Legal Document Graph Schema (ILDGS), a first-of-a-kind knowledge graph schema for representing the structure and entities referenced within legal documents, which Kanon 2 Enricher natively outputs to. In the interests of supporting open legal AI and data research, we’ve made ILDGS freely available under the CC BY 4.0 license.
Kanon 2 Enricher is available for use today via the Isaacus API.
We thank Harvey, KPMG Law, Alvarez & Marsal, Clifford Chance, Clyde & Co, Carey Olsen, Smokeball, Moonlit, and LawY, among many others, for being part of the exclusive Isaacus Beta Program, which was instrumental in improving Kanon 2 Enricher before its release.
16 March 2026: Kanon 2 Enricher can now be self-hosted via the AWS Marketplace.
An interactive 3D map of almost every Australian High Court case since 1903 clustered by area of law and linked and classified by citations produced using Kanon 2 Enricher to extract, disambiguate, and classify citations alongside Kanon 2 Embedder for reducing decisions to a three-dimensional space where semantically similar decisions are closer together. You can create maps of your own data using our semantic mapping cookbook.
Kanon 2 Enricher is the world’s first hierarchical graphitization model

Kanon 2 Enricher belongs to an entirely new class of AI models known as hierarchical graphitization models.
Unlike universal extraction models such as GLiNER2, Kanon 2 Enricher can not only extract entities referenced within documents but can also disambiguate entities and link them together, as well as fully deconstruct the structural hierarchy of documents.
Kanon 2 Enricher is also different from generative models in that it natively outputs knowledge graphs rather than tokens. Consequently, Kanon 2 Enricher is architecturally incapable of producing the types of hallucinations suffered by general-purpose generative models. It can still misclassify text, but it is fundamentally impossible for Kanon 2 Enricher to generate text outside of what has been provided to it.
Kanon 2 Enricher’s unique graph-first architecture further makes it extremely computationally efficient, being small enough to run locally on a consumer PC with sub-second latency while still outperforming frontier LLMs like Gemini 3.1 Pro and GPT-5.2, which suffer from extreme performance degradation over long contexts.
In all, Kanon 2 Enricher is capable of:
- Entity extraction, disambiguation, classification, and hierarchical linking: extracting references to key entities such as individuals, organizations, governments, locations, dates, citations, and more, and identifying which real-world entities they refer to, classifying them, and linking them to each other (for example, linking companies to their offices, subsidiaries, executives, and contact points; attributing quotations to source documents and authors; classifying citations by type and jurisdiction; etc.).
- Hierarchical segmentation: breaking documents up into their full hierarchical structure of divisions, articles, sections, clauses, and so on.
- Text annotation: tagging headings, tables of contents, signatures, junk, front and back matter, entity references, cross-references, citations, definitions, and other common textual elements.
Kanon 2 Enricher is already in use
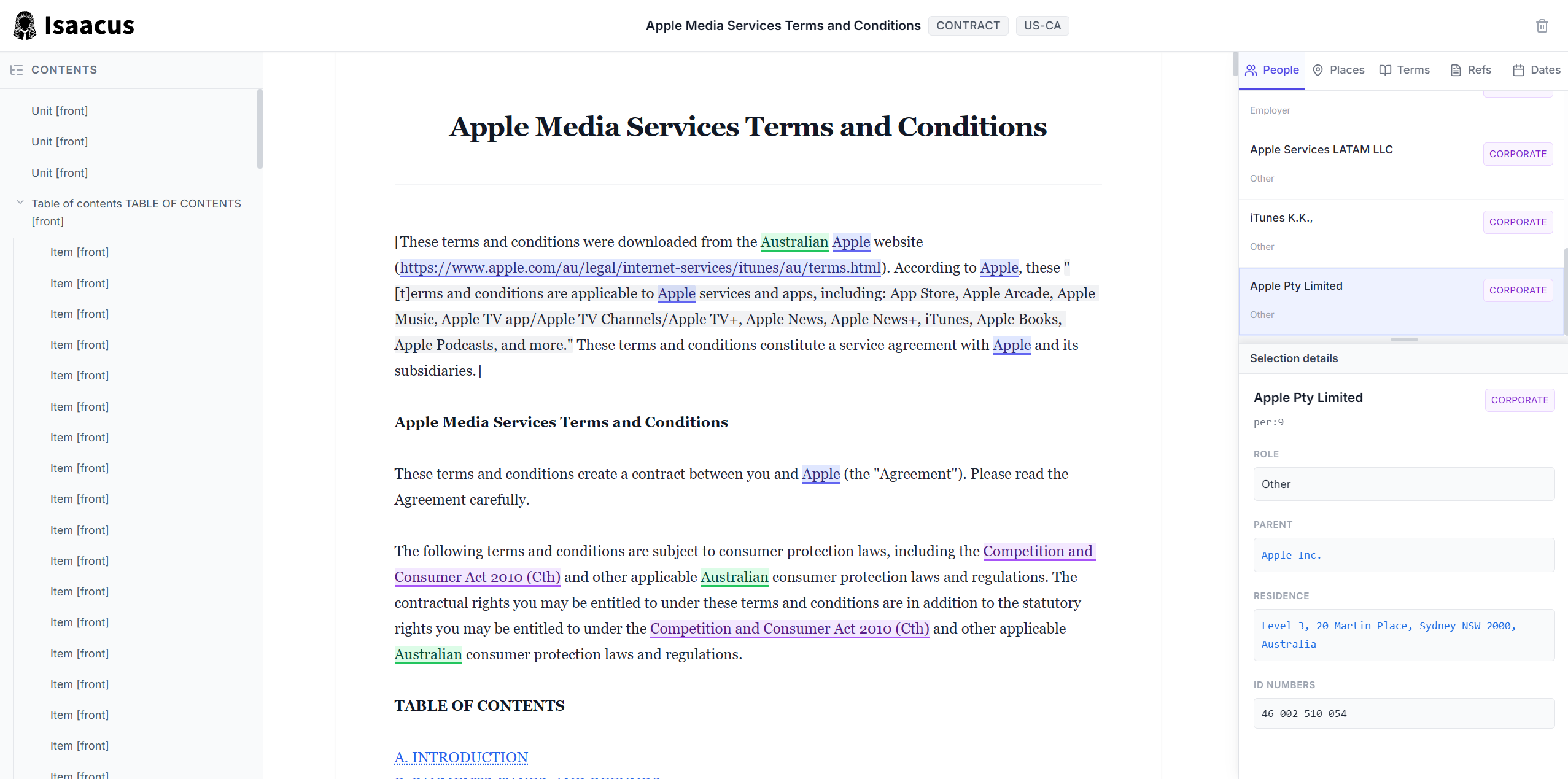
Apple’s terms of service enriched by Kanon 2 Enricher and rendered in an interactive ILDGS document viewer available as a cookbook.
The massive range of features supported by Kanon 2 Enricher makes it useful for a myriad of applications, from financial forensics to legal research.
For example, through the Isaacus Beta Program, which granted a select group of trusted design partners exclusive access to Kanon 2 Enricher, we saw a Canadian government leverage Kanon 2 Enricher to build a knowledge graph of thousands of federal and provincial laws to help accelerate regulatory analysis. Elsewhere in Europe, we saw Spinal, a startup building AI agents for accounts receivable, integrate Kanon 2 Enricher into their contract ingestion and enrichment pipeline, finding “the speed and accuracy of [Kanon 2 Enricher] to be amazing!”. Other notable applications of Kanon 2 Enricher include a new vendor due diligence tool, a government-facing policy intelligence platform, and an analysis of Canberra child care incidents from 2020 to 2025.
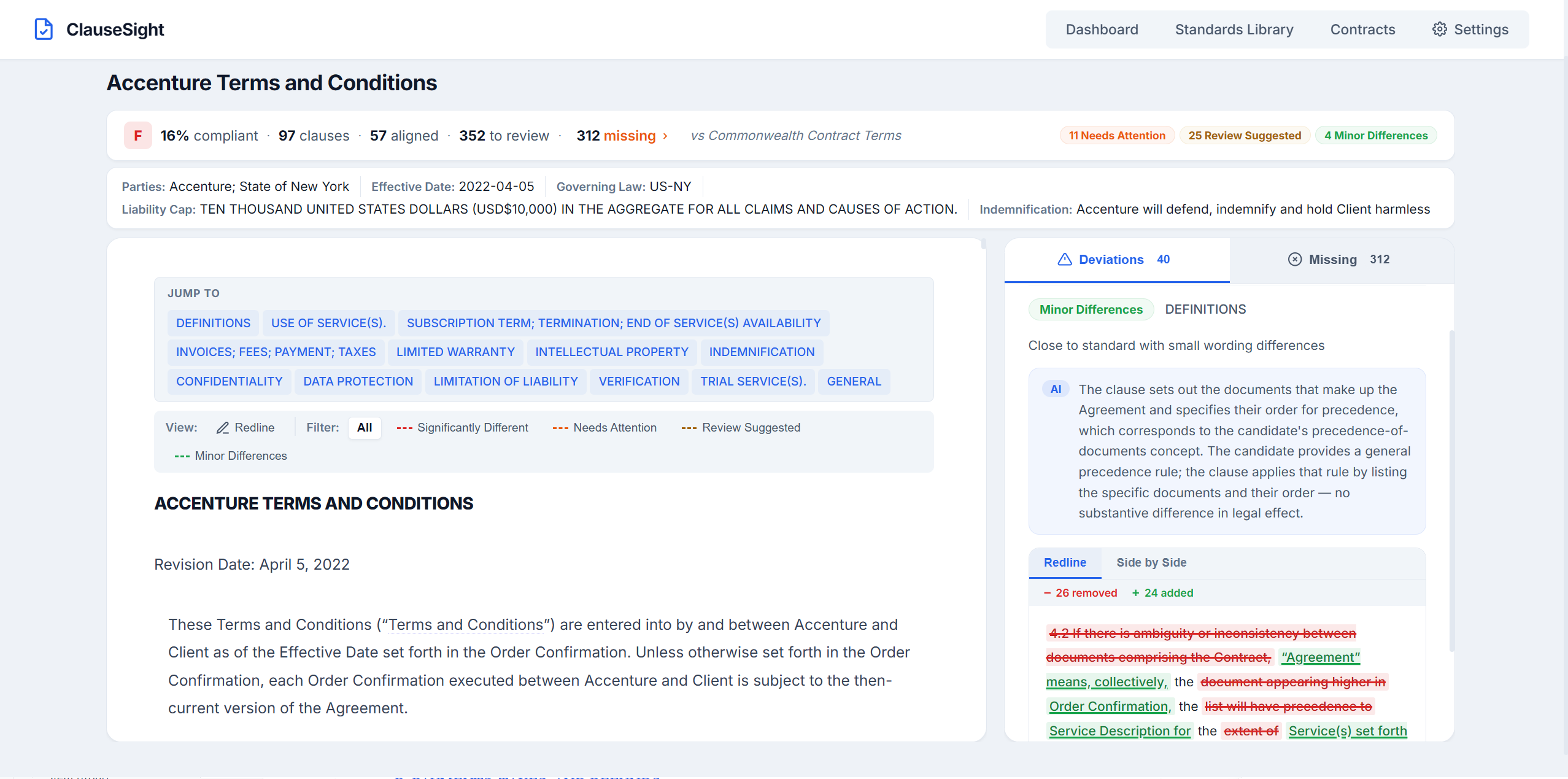
The ClauseSight vendor due diligence tool, powered by Kanon 2 Enricher, Kanon 2 Embedder, and Kanon Universal Classifier.
In total, there were 102 participants in the Isaacus Beta Program, including Harvey, KPMG Law, Clyde & Co, Cleary Gottlieb, Alvarez & Marsal, Khaitan & Co, Gilbert + Tobin, Smokeball, Moonlit, LawY, Lawpath, UniCourt, and AccuFind. We thank each and every one of them for being amongst the first to play with Kanon 2 Enricher and for providing critical early feedback that helped improve Kanon 2 Enricher ahead of its release.
Over the coming weeks and months, we will be releasing our own applications built atop Kanon 2 Enricher such as a new LLM-powered semantic chunking mode in semchunk, a new Python package for automatically converting plain text into Markdown, and a first-of-a-kind public knowledge graph of laws, regulations, cases, and contracts from around the world, which can then be ingested into your own systems.
Kanon 2 Enricher is an architectural masterpiece
As the first hierarchical graphitization model, Kanon 2 Enricher was built entirely from scratch. Every single node, edge, and label representable in the Isaacus Legal Document Graph Schema (ILDGS) corresponds to one or more bespoke task heads. Those task heads were trained jointly, with our Kanon 2 legal encoder foundation model producing shared representations that all other heads operate on. In total, we built 58 different task heads optimized with 70 different loss terms.
In designing Kanon 2 Enricher, we had to work around several hard constraints of ILDGS such as that each entity must be anchored to a document through character-level spans corresponding to entity references and all such spans must be well-nested and globally laminar within a document (i.e., no two spans in a document can partially overlap). Wherever feasible, we tried to enforce our schematic constraints architecturally, whether by using masks or joint scoring, otherwise resorting to employing custom regularizing losses.
One of the trickiest problems we had to tackle was hierarchical document segmentation, where every heading, reference, chapter, section, subsection, table, figure, and so on is extracted from a document in a hierarchical fashion such that segments can be contained within other segments at any arbitrary level of depth. To solve this problem, we had to implement our own novel hierarchical segmentation architecture, decoding approach, and loss function.
Thanks to the many architecture innovations that have gone into Kanon 2 Enricher, it is extremely computationally efficient, far more so than a generative model. Indeed, instead of generating annotations token by token, which introduces the possibility of generative hallucinations, Kanon 2 Enricher directly annotates all the tokens in a document in a single shot. Thus, it takes Kanon 2 Enricher less than ten seconds to enrich the entirety of Dred Scott v. Sandford, the longest US Supreme Court decision, containing 111,267 words in total. In that time, Kanon 2 Enricher identifies 178 people referenced in the decision some 1,340 times, 99 locations referenced 1,294 times, and 298 documents referenced 940 times.
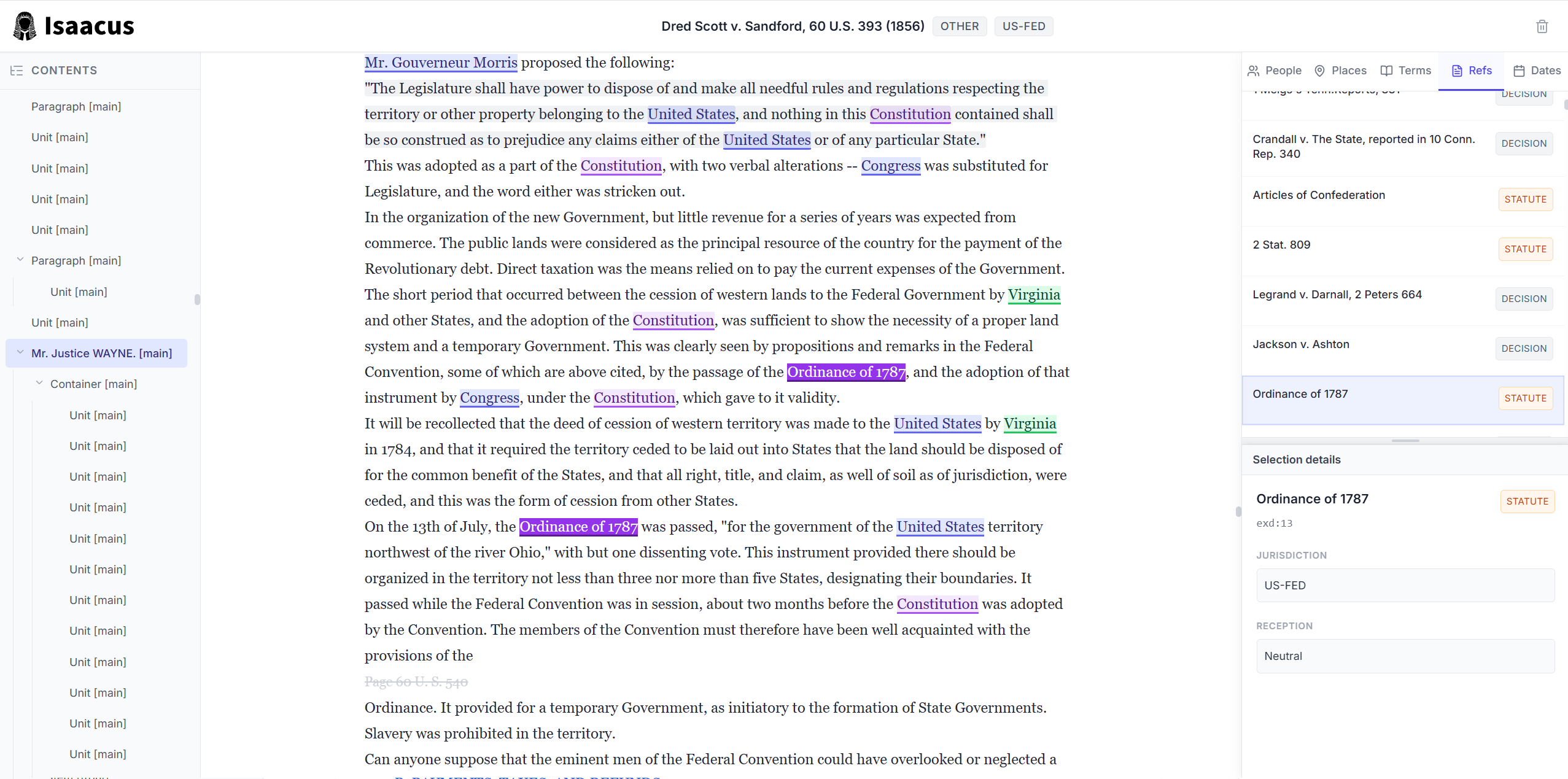
Dred Scott v. Sandford enriched by Kanon 2 Enricher and rendered in an interactive ILDGS document viewer available as a cookbook.
Kanon 2 Enricher can handle documents far longer than 100k tokens. Although its native context window is 16k tokens, we’ve also built our own algorithm for chunking long documents and then stitching the results back together intelligently to form a single enriched document, with only a minimal diminution in accuracy.
Kanon 2 Enricher represents a significant leap forward not only in the emerging field of knowledge graphitization but also in legal AI, where overhyped, underperforming systems are just as abundant as the poorly structured data they are meant to make sense of.
Kanon 2 Enricher is only the beginning
Given the overwhelming interest we’ve seen in Kanon 2 Enricher, we’re planning on soon releasing our own public legal knowledge graph backed by Kanon 2 Enricher called the Blackstone Graph. The Blackstone Graph will cover laws, regulations, cases, contracts, and regulatory documents from across the world, including the US, UK, Australia, Canada, New Zealand, Ireland, Singapore, and Europe. The Blackstone Graph will integrate Kanon 2 Enricher alongside our state-of-the-art retrieval models Kanon 2 Embedder and Kanon 2 Reranker, which is in active development. Unlike other major legal data providers, we plan on allowing anyone to build their own applications atop the Blackstone Graph, removing the need to maintain your own copies of public legal data. Interested parties are encouraged to apply to the Isaacus Beta Program, which will grant early access to the Blackstone Graph once it enters beta.
In addition to the Blackstone Graph, we’ve already begun work on Kanon 2 Enricher’s successor, Kanon 3 Enricher, which will offer first-class support for custom extractions, linking, and classification. After Kanon 3, will come Kadi, the first legal reasoning model, trained on millions of real reasoning traces from legal practitioners. Kadi will most likely arrive towards the end of this year.
To get notified about new products and models, join our platform and then follow us on LinkedIn, X/Twitter, or Reddit.